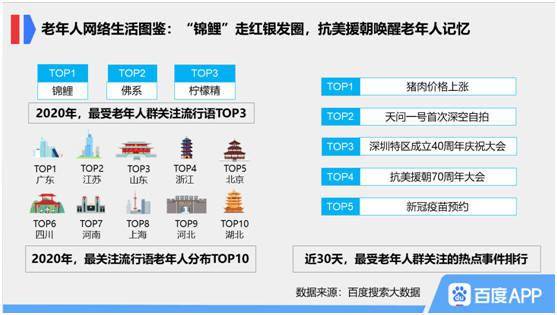
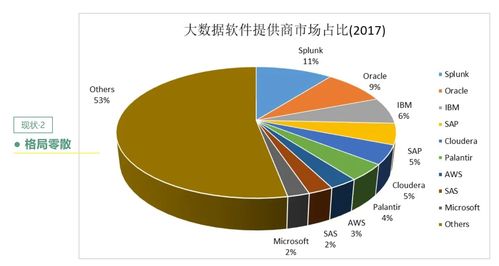
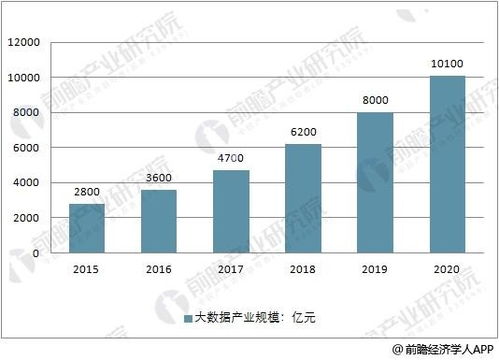
2016年上半年,大數據領域風云激蕩,技術與應用的結合日益緊密。一批創新性強、實用性高的產品與服務嶄露頭角,不僅推動了數據處理能力的邊界,更在實時分析、機器學習、云服務及數據安全等方面帶來了革命性體驗。以下盤點了上半年十款最具代表性的酷炫大數據產品與服務,它們共同勾勒出當時數據智能生態的蓬勃圖景。
- Apache Spark 2.0(預覽版):作為大數據處理框架的明星,Spark 2.0預覽版在2016年上半年發布,其核心亮點在于引入了全新的“結構化API”(DataFrame和Dataset的統一),并大幅提升了性能與易用性,讓流處理和批處理的編程模型更加一致,被譽為一次重大飛躍。
- Amazon Athena:亞馬遜AWS推出的一款交互式查詢服務,無需管理基礎設施,即可使用標準SQL直接分析存儲在S3中的數據。它以其無服務器架構和按掃描數據量付費的模式,極大降低了即席查詢的門檻和成本,令人耳目一新。
- Google Cloud Dataproc:谷歌云平臺推出的托管式Spark和Hadoop服務。它允許用戶在幾分鐘內創建可定制的集群,并集成了谷歌云的其他服務(如BigQuery、Cloud Storage),因其快速的啟動速度和精細的成本控制(支持按秒計費)而備受青睞。
- Microsoft Azure Data Lake Store & Analytics:微軟推出的超大規模數據湖存儲與分析服務。Data Lake Store提供無限制的存儲,支持任何類型的數據;而Data Lake Analytics則提供了基于YARN的、高度可擴展的分布式分析服務,使用類似SQL的U-SQL語言,簡化了大數據處理流程。
- Tableau 10.0:數據可視化領域的領導者Tableau發布了其10.0版本,新增了跨數據庫聯接、簇分析、靈活的時間序列分析等功能,并增強了與Spark、Hadoop等大數據平臺的集成,使得從大型數據集中快速發現洞察變得更加直觀和強大。
- Cloudera Data Science Workbench:Cloudera推出的自助式數據科學工作臺,允許數據科學家使用自己喜歡的開源工具(如Python、R、Scala)直接在安全的Hadoop集群上進行探索、實驗和模型部署,打破了數據科學與生產環境之間的壁壘。
- Splunk Machine Learning Toolkit:Splunk將其強大的機器學習和預測分析能力打包成工具包,使普通用戶也能在Splunk平臺上利用流行的算法庫(如Scikit-learn)來構建和部署機器學習模型,將機器學習無縫融入運維和業務分析場景。
- Talend Big Data Platform v6:Talend發布了其統一的大數據平臺版本,提供了更豐富的組件和連接器,支持Spark Streaming、Storm等流處理框架,并通過圖形化設計器大幅簡化了復雜數據集成和數據質量作業的開發,提升了開發效率。
- Confluent Platform 3.0:基于Apache Kafka的Confluent平臺推出了3.0版本,強化了Kafka作為實時數據流中樞的地位。新版本提供了更完善的Kafka Streams API(用于流處理)、更強大的Kafka Connect(用于數據集成)以及改進的管理控制臺,助力企業構建實時數據管道。
- IBM Data Science Experience:IBM推出的云端協作式數據科學平臺,集成了開源工具(如RStudio, Jupyter notebooks)和IBM Watson的數據分析服務。它強調團隊協作和模型生命周期管理,旨在為數據科學家提供一個端到端的云端工作環境。
**:2016年上半年的這些產品與服務,清晰地呈現出幾個關鍵趨勢:云化與無服務器架構降低了使用門檻;實時流處理成為標配;數據科學與機器學習的平民化進程加速;SQL的復興與統一的分析接口備受重視;可視化與交互體驗**持續提升。這些創新不僅在當時酷炫,更為后續數年大數據技術的普及與深化奠定了堅實的基礎,持續驅動著各行各業的數字化轉型。